

聚点股 GPTImage2.0发布:太惊艳了,UI工程师和PPT工程师要绝望了
【GPTImage2.0发布:太惊艳了,UI工程师和PPT工程师要绝望了】我打了一段文字。30秒后,GPT吐出了一张图。
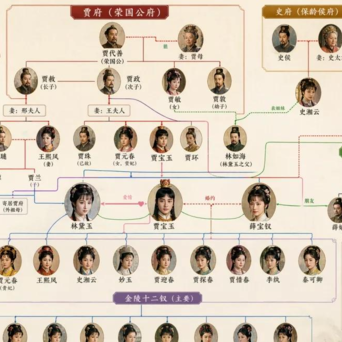
我的prompt:生成一张红楼梦人物关系图谱,中国古典风格,包含主要家族(贾府、史府、王府、薛府),用不同颜色的连线表示血缘、婚姻、主仆关系,每个角色配有头像,底部有金陵十二钗横排展示。
我的评价:这图放在任何红楼梦的科普公众号里,都可以直接当封面。排版密度、色彩搭配、信息层级——都达到了专业出版物的水准。最让我震惊的是,它理解了"血缘关系"和"婚姻关系"要用不同颜色区分这件事——这不是"画一张图",这是"做信息可视化"。
UI工程师和 PPT工程师为什么要"绝望"
因为它们恰好覆盖了 GPT Image 2.0 最强的两个品类。
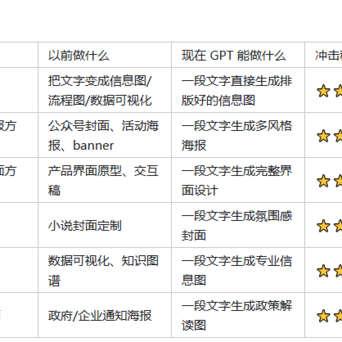
被冲击的岗位如图2,冲击程度最高的是PPT设计师——因为PPT的本质就是"信息可视化排版",而这恰好是GPT Image 2.0最擅长的。你不再需要一个设计师来"把文字排好看"——模型直接理解"什么排法好看"。
暂时安全的岗位如图3,"暂时"这两个字很重要。因为模型的迭代速度是按周计算的,不是按年。
可能有人会问:Midjourney、Stable Diffusion、DALL-E 3——这些 AI 绘画工具不早就有了吗?GPT Image 2.0有什么不一样的?
区别在于:理解力。
Midjourney擅长"画好看的图"——你给它一个视觉描述,它给你一张美学上不错的图。但你让它"生成一个直播PK界面",它大概率给你一张两个明星在打拳的图——它不理解"直播PK界面"是什么意思。
GPT Image 2.0不一样。它理解"直播PK界面"是什么——因为它读过互联网上所有的直播界面截图、产品文档、用户讨论。它不是"画"了一个界面,它是"理解"了界面这个概念,然后"生成"了一个符合这个概念的图。
写到这里,我才意识到一个更大的趋势:
文字和图像之间的"翻译损耗"正在消失。
以前:你想做一个信息图 → 你写需求文档 → 设计师理解需求 → 设计师出初稿 → 你提修改意见 → 设计师改 → 你再提 → 设计师再改 → 定稿。中间每一环都有信息损耗。
现在:你想做一个信息图→你写一段文字→图出来了。
中间环节从 5-6 步变成了 1 步。信息损耗从30%+ 变成了接近0%。
这意味着什么?意味着"表达能力"变得比"设计能力"更重要。你不需要会PS,你需要会"用文字描述你想要的东西"。
但这其实是一个好消息——因为会写字的人,比会用PS的人多得多。

东南配资提示:文章来自网络,不代表本站观点。
- 上一篇:亦丰策略 万邦达:公司2025年度实现营业收入2615287311.80元
- 下一篇:没有了








